Metadata is crucial for Digital Marketing
14.11.2015, Spartan asiantuntija
This post is not based on Gartner or any other research, but my own observations on projects I have been carrying out over the last few years.
- All organizations seem to suffer from bad quality of data as well as bad quality of metadata (the data about data or content).
- Most of the organizations are not even aware of the fact that great deal of business problems are due to information management problems.
- …and those who have, yet put their money in “real business challenges = IM technology” and overlook the data/metadata issues.
- Local agile solutions in business units cause severe deadlocks for the data integrations at the global level.
Structured data (schema based metadata) by schema.org has become guideline for on-page mark up, helping search engines to understand the information on webpages and provide richer results. Let’s explore some real life cases where bad (meta) data management caused business failures.
Business problems in real life – caused by poor metadata management
I have witnessed, or my colleagues have told me stories, such like:
- RTD is blind for business metadata.
A large manufacturer had to switch off their real time decision engine from the campaign page, since the RTD-box would never show any content regarding their brand new product. The new product had not yet gained any scores from users to which their RTD-engine could use to give recommendations about the new product. RTD-engines are typically overly self-containing in reacting to users’ behavior, but rigid in combining external business rules. As an example when marketing wants to change rules to boost visibility of the new product, regardless of user’s profile or history. The required change in RTD rules is a manual operation and can difficult or impossible.
- Bad metadata in web pages cripples SEO.
Metadata in HTML-content plays a crucial role in SEO. In most of the web publishing projects I have witnessed low quality of available metadata, which comes with the content items to the assembly and transformation engine. Often no metadata exists, or it is inconsistent and not correctly describing the content and/or the product the page is marketing. One team decided to switch off the metadata based index enrichment because all the metadata for intranet documents were the same, based on the document template and just causing more noise than relevancy.
- Inconsistent use of identifiers kills web analytics.
A web analytics team had to use text mining practices in order to get (guess) the big picture of which campaigns were ran globally, which products were currently marketed and which type of content was actually published. It was also impossible to conclude which content correlates to increased sales of products in web stores. There was no consistent use of unique identifiers and categories, instead each systems relied on ad-hoc hash tags and locally generated page metadata. All this inconsistency just caused unreliable analytic results after the laborious efforts.
- Anarchy in the local systems prevents merging of information.
A company built a centralized metadata hub to harmonize content categorization (tagging etc.). The plan was to merge data from different sources. The mapping exercise became next to impossible as source systems were using their own categories and ad-hoc logics. All kinds of workarounds were implemented in the eve of eCommerce. What was tragicomic was that the master data management system was in place, but obviously not accessible or failed in their internal marketing, since not that many systems complied their reference data.
- Web pages are not providing meaningful information for search engines
So that consumers could find your site and would pay attention on your web shop products, store locations etc. while browsing Google search results. Often store and product data is not even showing up in the search results.
Model for digital marketing 360 metadata
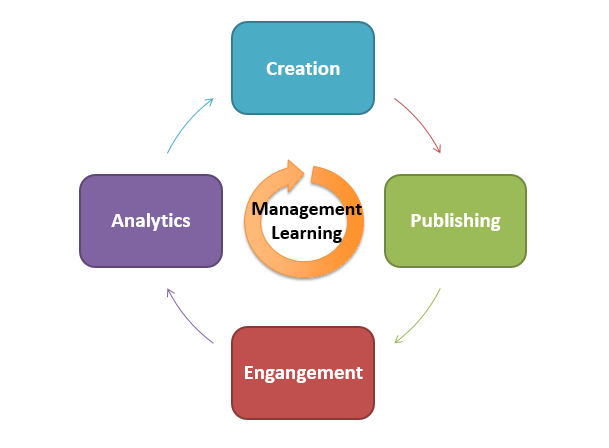
To cut corners, one can say – all business objects have a structure and a lifecycle. By combining those viewpoints, I have modeled a high-level structure for the metadata according to the phases of lifecycle.
Lifecycle of the metadata
If you consider using metadata for digital marketing, say using full potential of metadata over the content life for targeting, the lifecycle phases are:
- Creation of substance, when the author also has the best opportunity to create descriptive metadata.
- Managing and publishing the substance, when business can add the contextual metadata.
- Engagement of the substance, when users can contribute their feedback to be added on.
- Analytics: what has happened in similar situations, when behavioural metadata can be merged in?
Now it is quite straightforward to derive the metadata high-level structure.
Picture of 360-view metadata
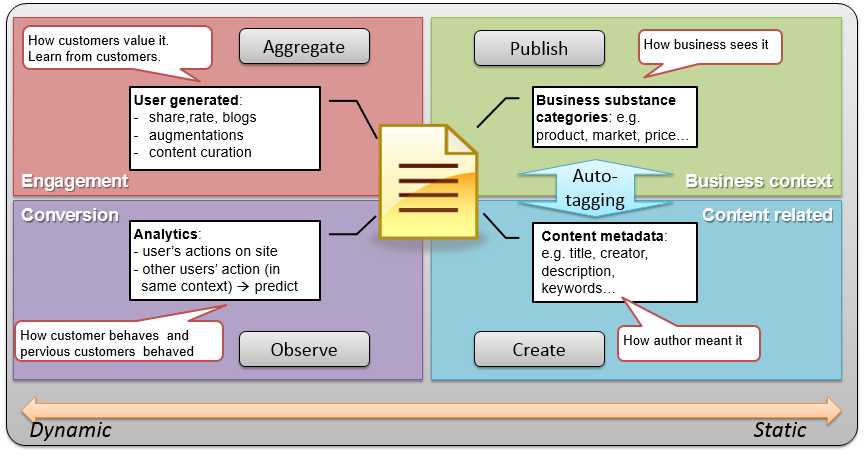
I call the high-level structure the Fundamental types of metadata for 360 view. And if you leave one type out – or viewpoint if you will – it causes a distorted or incomplete picture. The picture is supposed to tell you few basic things:
- the shared meaning of content metadata – towards common language
- what business related metadata can be added on – understanding the context
- how consumers value and annotate the actual delivered substance – learning from feedback
- observing how people act (with the content) – learning from behavior of the consumers.
In order to depict characteristics of 360-view metadata, I created these four metadata archetypes:
- Descriptive metadata is mainly created during the content creation or just when the content is submitted to CMS. For the sake of productivity and the author’s mental health – automated tagging should be used (such as, Power Tagging by PoolParty).
- Business context metadata is partially added during the submission but typically applied when the content item is assembled or repurposed as part the page or publication. Companies use taxonomy, categorization or even business ontology systems to better manage this type of contextualization.
- User created metadata is typically aggregated from several feeds and systems. In social media people are sharing, commenting and rating your product using potentially your own web site but mainly other common platforms such as Facebook, Twitter, Bazaarvoice etc. Feedback can be crowd sourced directly from users, say from user forums or shout-box, but also using indirect web analytics which tap into APIs of the platforms or run some type of web page crawling. There are also several third parties providing user feedback and curation (see a list of tools).
- Analytics metadata is created based on any kind of observed data. It can be both static search and browsing history based data or real/near real time behavioral data captured during the session. Analytics data on users’ actions can be also retrieved from various social platforms and third parties and then merged with site origin data.
We can now pull everything together as a four-field concept (as any consultant does trying to simplify complex things with an equally complex picture):
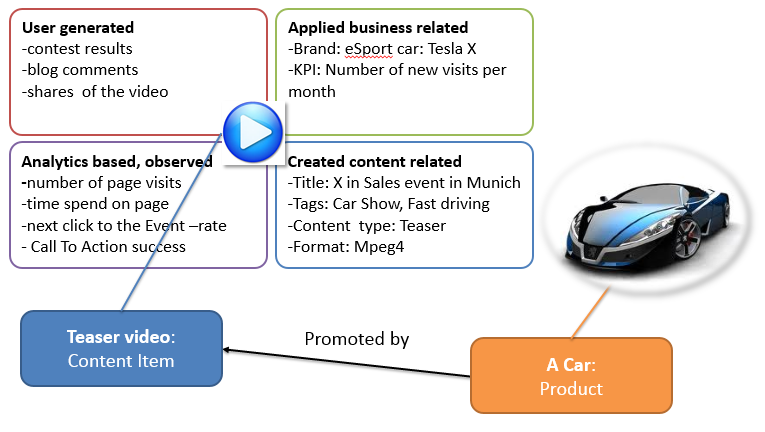
Next we have an imaginary case of car sales event, which is promoted by a video on car company’s campaign site. Four type of metadata has been added over the content item lifecycle.
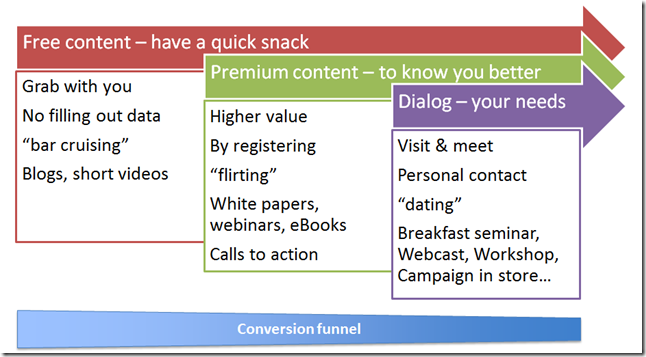
Lastly, let’s look at the content as part of customer relationship plan.
Placing the good metadata on web pages
So, all this valuable metadata should be collected, contextualized, structured and then published on the web pages in order to get boosted SEO and to provide more meaningful search results to hasty consumers. I bet, most of the needed semantic data about products and their ”consumer context” is available somewhere in your company’s product and marketing processes, but not retained and piped through the complex an disconnected systems to the web page publishing as a high-quality metadata. That has been the case in all large companies whom I have consulted. What comes to the structured page metadata, there are schemas published and clear guidelines by big G for example, to follow in order to implement injection of metadata to the HTM mark up part in your publishing environment.
But why are Google and other big boys giving this all out? I guess this is part of their Knowledge graph initiative to semantically model the entire world? But, it makes you also wonder if what G says is biased, since it is in their interests to grab as much as possible meaningful (codified) data from your pages to enlarge their knowledge graph and also – most importantly – to make money from your data.
Shaping up the data quality, harmonization of identifiers for business objects, integrating data flows and establishing a common terminology may take half a decade. It is slow because it is about educating people and revamping the corporate culture, and not just buying new technology. By choosing the right approach and by using semantic technology savvy tools – the data integration may be much easier than you think. For more information, search for linked enterprise data.
Intelligent content as part of customer relationship plan
To peek into my next post, I have simplified the process of conversion funnel and connected three basic types of information: free content, premium content and dialog with customer. Keep tuning in for the upcoming post. I will tie these content items to the four archetypes of the metadata. Not to forget linked open data approach either.